
A few weeks ago I did a talk at AI Bootcamp here in Melbourne on how we can build a serverless solution on Azure that would take us one step closer to powering industrial machines with AI, using the same technology stack that is typically used to deliver IoT analytics use cases. I demoed a … Continue reading Control IoT Devices Using Scala on Databricks (Based on ML Model Output)
Tag: IOT
Stream IoT sensor data from Azure IoT Hub into Databricks Delta Lake

IoT devices produce a lot of data very fast. Capturing data from all those devices, which could be at millions, and managing them is the very first step in building a successful and effective IoT platform. Like any other data solution, an IoT data platform could be built on-premise or on cloud. I'm a huge … Continue reading Stream IoT sensor data from Azure IoT Hub into Databricks Delta Lake
Use Streaming Analytics to Identify and Visualise Fraudulent ATM Transactions in Real-Time
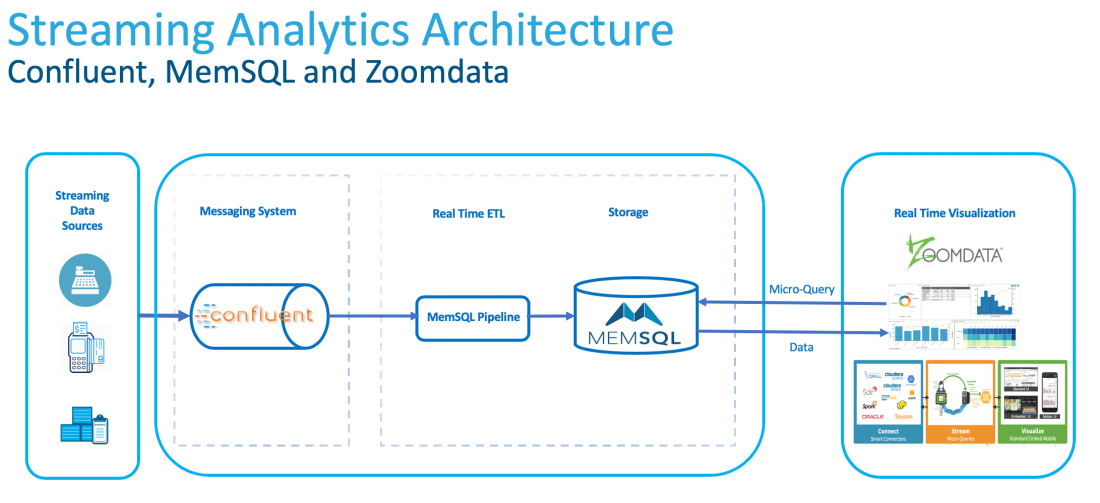
Storing and analysing big amounts of data is not the differentiator of successful companies in the process of decision making anymore. Today's world is about how fast decision makers are provided with the right information to be able to make the right decision before it’s too late. Streaming Analytics is correctly referred to as Perishable … Continue reading Use Streaming Analytics to Identify and Visualise Fraudulent ATM Transactions in Real-Time
