If you have been working in Big Data, you have definitely heard of Hive. Apache Hive is the data warehouse infrastructure build on top of Hadoop. I did a presentation on how to best use Apache Hive and few tips on how to best use it for one of our clients last week that I would like to share with you here. This is designed to help developers and analysts writing better queries and get result faster from Hive.
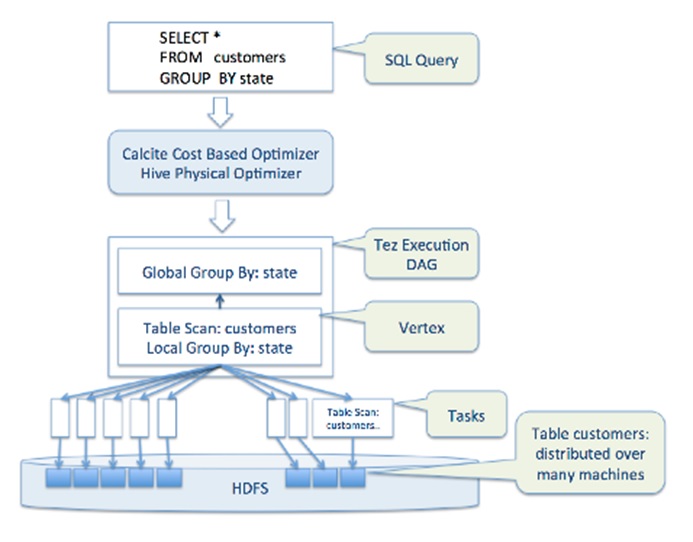
To best understand how Hive works, we need to picture it as a file system. Data in each table is divided into partitions based on partitioning strategy and each partition is stored as a physical file in hdfs. Files are replicated as many times as hdfs’s replication factor dictates, which is usually 3.
Use Hive Partitions
As you have probably guessed, partitioning can be used to limit the files our query scans to complete its job, instead of having to go through each and every file. Using partitions is more efficient than creating and then using indexes as well, as it physically limits the set of files each query scans.
The question for a developer or analyst would then be “How can I know what partitions exist for a table?” SHOW PARTITIONS are the keywords to achieve this. It can be used in Hue, Aginity, Hive CLI, or any other way you would use to query Hive tables. Partitions could be used in a query’s where clause, the same way we filter the query on any other column. you can see that as well as the difference using a partition in a query makes below:

Check Query Plan
Like any other database, hive provides a way to see the query plan it’ll use to execute the query. A query plan is the set of steps and commands the DB engine takes to execute the query and produce the result. You can use EXPLAIN in the beginning of your query to see the query plan, or use Explain button in Hue to do the same:
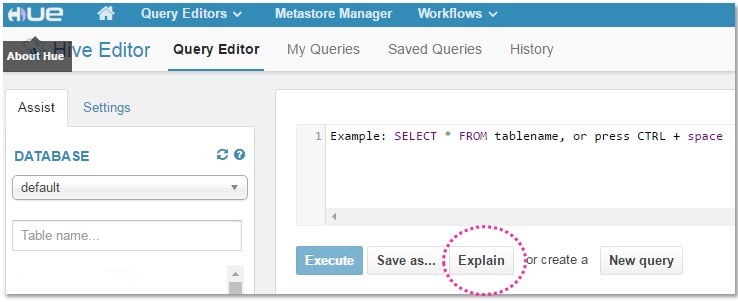
I used the query we looked at previously to explain a couple of points on what to look for when checking query plans:
- TableScan: As its name implies, this step reads (scans) the tables for a purpose. In this example, we can clearly see that our filter on src_date is applied to the table scan. And since this column is our partition column, Hive knows clearly which files it should open and read to get the result it is looking for
- Check the step at which the filter on partition column is being applied. The sooner this filter is applied, the less records will be passed to the downstream steps of query execution and the more efficient it is.

Hive and Joins
When joining 2 tables, apply as much filter as possible on the bigger table in join itself, instead of where clause. This limits the number of records being joined to the smaller table and therefore, less records to work on or filter later.
Using all these techniques will help getting faster results from Hive, but nothing is more important than writing a good query. I was contacted by one of the analysts working for my client a few weeks ago, complaining that his query takes more than 12 hours to run. At the very first glance I realized he is scanning one of the biggest tables we have 5 times, with no filter on partitioned column. After spending a good hour on it and re-writing the query, we managed to get the same job done in about 25 minutes.
So, please write good queries. And always filter on partition column. Good luck!
